
AobaZeroはDeepMind社のAlphaZeroの追試をその目的としたプロジェクトであった。教師生成(棋譜生成)の部分をアウトソーシング化(?)してあり、誰でもGoogle Colabで棋譜生成に協力できるようになっていた。生成された教師は公開されており、誰でも利用することができた。昨年の電竜戦で優勝したGCTもAobaZeroの棋譜を利用していたし、他のdlshogiチルドレン(?)も、AobaZeroの棋譜にはずいぶんお世話になっているはずである。
しかし、AobaZeroの棋譜にはいくつかの問題点があった。
1) 入玉宣言勝ちを理解していない。これは、評価値が一定以上になったときに試合を(確率的に)打ち切るようにしているためで、途中のバージョンから徐々に入玉宣言勝ちの割合が減っているようだ。(たぶん悪い循環に入っている)
下図はKristallweizenと1手800playoutで対戦させた場合の宣言勝ちの割合。
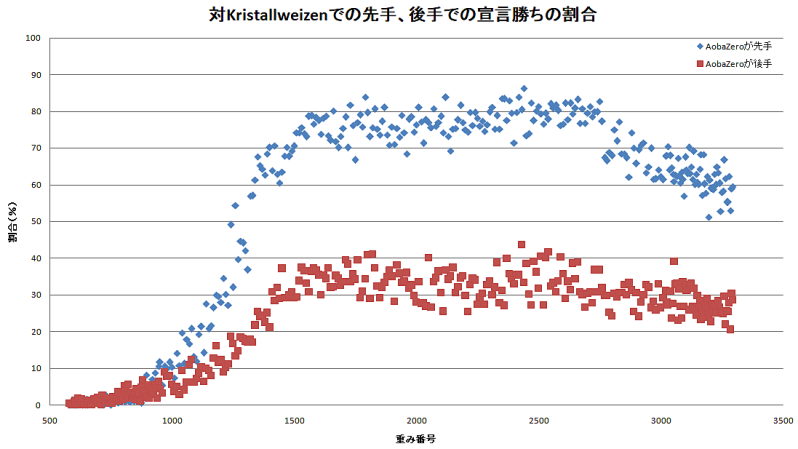
AobaZeroの教師をdlshogiでの学習に利用する場合、宣言勝ちの割合が低下したバージョンの棋譜を使わないというのも大切なところだ。いまのところ、こういったバッドノウハウがたくさんある。
2) 入力特徴量に利きがないので長い利きを理解していないことがある。
dlshogiには入力特徴量に利きがある。それゆえ10ブロック(のResNet)でもそこそこ強いのだが、AobaZeroの場合、入力特徴量に利きがないので20ブロックでも長い利きを見落として、それゆえ棋力を損ねているところがある。
3) 詰将棋ルーチンを搭載していない。
dlshogiはdf-pnによる長手数の詰将棋ルーチンや、leaf nodeでのN手詰め(デフォルト 5手詰め)を呼び出しているが、AobaZeroにはそれがない。なので詰みを見逃すことや、詰みより入玉勝ちを目指す傾向にある。
4) 1手が800 po(playout)で生成されているため、棋譜の質が低い。
poは、1手指すのに調べた局面数だと思って欲しい。
// 厳密には少し違うが、大雑把にはそんな理解で問題ない。
dlshogiではもうちょっと多いpo数で教師を生成しているそうで、800 poはちょっと少ない印象を受ける。
// GCT電竜のノートブックで公開されたdlshogiのselfplay(自己対局させた棋譜)ももっと高いpoで生成されたもののようだ。
// GCT電竜のノートブック : https://colab.research.google.com/drive/1beq7ncmE16lIvOhGTHLzxOwaQNzAcUqh?usp=sharing
それらの欠点にも拘らず、AobaZeroの棋譜にはメリットもある。
5) 棋譜が大量に無償で公開されている。
何十億局面もある。(現在3980万棋譜。40億局面ぐらい?) 数としては申し分ない。
6) 戦型がある程度ばらついている。
GCT電竜のノートブックにあるdlshogiのselfplayは開始局面の都合か、開始局面からのrandom moveの手数(デフォルト4)の都合か、開始局面にかなり偏りがあるようである。そのへんを補う意味がある。
これらから総合すると、もっと高いpo数(もしくは、もっと強いソフトで)で頭金まで対局してくれた棋譜が大量にあれば、それを使うだけで(自分では教師生成せずともいいので)誰でも最強の将棋ソフトが作れちゃうのになぁという期待はある。
// ただで棋譜をもらっておいて、大変厚かましい話であることは承知している。
そんななか、AobaZeroプロジェクトは、AlphaZeroの追試を終了することを発表した。
|
1 2 3 4 5 |
2019年3月に開始して2年2か月で3980万棋譜を作成しました(AlphaZeroは2400万棋譜)。 これまで棋譜作成に協力していただいた皆様、バグを報告したり遊んで下さった方々に感謝いたします。 AlphaZeroには推定で154 Elo(後手番では86 Elo、先手番で377 Elo)負けています(後述)。 |
これでAobaZeroのプロジェクトはなくなってしまうのかと思ったら、次は40ブロックに変更して学習(と棋譜生成)を継続するという発表があった。
そして、AobaZeroは40ブロックに変更したところ、いきなりR100も強くなっている。

800 po固定での計測なのであろうから、20ブロックと40ブロックの差がR100(ポテンシャルとしてはそれ以上)あるということだ。dlshogiの場合、そんなに強くはならない。
なぜ40ブロックでこんなに強くなったのかということなのだが、そもそも20ブロックが弱すぎたという話はある。つまり、上で書いたように、入力特徴量に利きがないので長い利きを見落としていたのが40ブロックになって改善された可能性や、詰将棋ルーチンがないので詰将棋が弱かったのが少し改善された可能性がある。
40ブロック→80ブロックのように増やして行ったときに同じくR100以上強くなるのであれば、将棋でも囲碁や画像認識で使うmodelのように多くのブロック数のmodelにしたほうが良いという話になる。(その学習に要するリソースのことは考えないものとする) ここのところは、どうなのかはまだわからない。
AobaZeroに関しては、40ブロックにしたことでR100以上強くなり、その強くなったソフトで生成された棋譜が今後、無償で公開され続けるのであろうから、それを使えば棋譜生成の計算資源のない人でも簡単に強豪ソフトと比肩するような将棋ソフトが作れるようになると思われる。
それと同時にAobaZeroがこのあとゴールデンウィークに開催されるWCSC31(第31回世界コンピュータ将棋選手権)で優勝する可能性が出てきた。
AWSにあるA100×8のインスタンスの場合、dlshogiで10ブロックだとGPUが1/3ぐらいしか使えていなかったが、40ブロックならGPUがフル活用できる。それどころか、AobaZeroは入力特徴量に利きがなく、詰将棋ルーチンも呼び出していないのでCPU側の負担は軽く、40ブロックの場合、おそらくA100×16でもGPUを使い切れるように思う。
GCPにはA100×16のインスタンスがあるから、これを使うなら、40ブロックのAobaZeroがWCSC31で優勝しても全然おかしくないわけである。
>> 40ブロック→80ブロック
増やすコツがあるんでしょうね。40の回路を生かしてるんじゃないのかなぁ。ビッグバンテストみたいなすべて組み合わせて一気に動かすのダメってみたいなのもある??知らんけど
20→40ブロックですが、学習時間は大したことないので、学習をやりなおしてるはずです。
// 教師生成が学習時間が桁違いにかかるので。(生成した教師はブロック数が変わってもある程度流用できる)