
囲碁AIの対局から学ぶことにより、「今の人類は、昔の人類に7割くらい勝てるようになってるイメージ」らしい。囲碁AIとの関わり方についてとても興味深いインタビュー記事がニコニコニュースに掲載された。インタビュアーは、『りゅうおうのおしごと!』の白鳥先生である。
いま囲碁界で起きている”人間とAI”の関係──「中国企業2強時代」「AIに2000連敗して人類最強へと成長」将棋界とは異なるAIとの向き合いかた
https://originalnews.nico/299273
ブロック数について
このインタビューのなかに、「40b(ブロック)」という表現が出てくる。これが何なのか、将棋AI、チェスAIではどうなっているのかについて軽く書いておきたい。

Deep Learningと言っても、そのなかで使われているモデルには様々なアーキテクチャー(内部構造)のものがある。いま、囲碁や将棋、チェスのAIで使われているのは、ResNet(レズネット)と言うモデルが主流である。これは次のようなブロックを複数個連結した構造になっている。
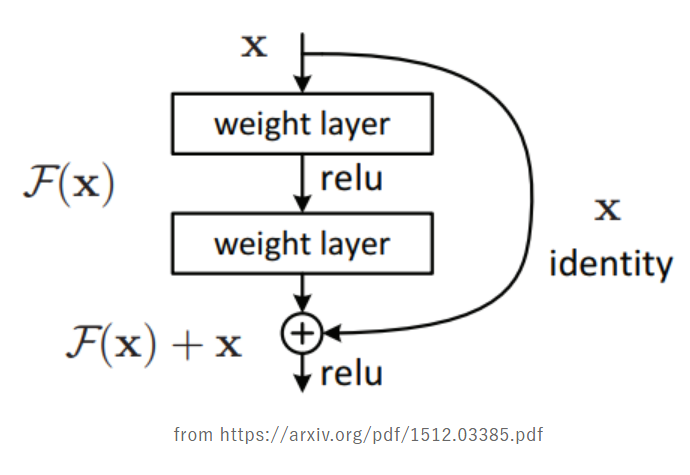
図で「x identity」と書いてあるのは、「x、そのままの値」ぐらいの意味で、前段の出力された値x を、次の段の直前のところにそのまま持ち越している。この持ち越したxの値は、内側(F(x)と書かれている)からの出力と足し合わせて、この段の出力としている。
ということは、この内側(F(x)と書かれている)では前段の出力と今回の出力との差を学習しているということである。このようにしたほうが、差分だけ学習すれば良いので学習部分の負担が少なくて済むし、段数が多くなった時にも後段まで入力情報が消失しにくくて都合が良いのである。
このように一つのブロックでは、前の段の出力と今回の段の出力との差を学習しているのがResNetの特徴であり、ResNetのResとは、residual(残差)の意味である。
ResNetは画像認識の分野で優秀な成果を挙げているが、囲碁や将棋、チェスのようなゲームの形勢判断も盤面を画像として入力して、局面の優劣度合いを出力するタスクであると考えるとResNetが適用できるのもさほど不思議ではない。
画像認識の最先端ではResNet以外のモデルも使われているが、囲碁や将棋、チェスではまだResNet以外の例はあまり聞かない。今後、ResNet以外を採用するソフトも出現してくるとは思うが、わりとResNetが適しているようではある。
なので、ソフト同士の大会で女の子のチームがあったからと言って「局面評価に使っているモデルは何ですか?」などと尋ねて
女の子「私達(のチーム)は、レズ(ResNet)なの」
などと言わせないように。
// そんなことを言う女の子はいない。
ブロック数と強さとの関係
上で書いたようにResNetは残差を計算する塊(ブロック)を連結した構成となっている。このブロックが多いほど層が深い(Deep)ということである。
このブロックの数が囲碁では40ブロックなのが主流なのである。ちなみに昨年の電竜戦で優勝した将棋ソフトのGCTは10ブロックである。AlphaZero(将棋)は20ブロックらしい。チェス(LeelaChessZero)では様々なブロック数のものが公開されている。
https://github.com/LeelaChessZero/lc0/wiki/Best-Nets-for-Lc0
チェスで主に使われているものとしては、
一番大きいもので、
・30 blocks x 384 filters
一番小さいもので、
・10 blocks x 128 filters:
のようである。
filter(フィルター)は、1つのブロックで扱うチャンネル数のことで、扱っている盤面画像の枚数とでも思ってほしい。ブロック数がネットワークの層の深さだとしたら、filter数は、ネットワークの幅である。幅が広いほど、層が深いほど、高い表現能力(≒学習能力)がある。
// フィルター数(チャンネル数)もブロック数に応じて増やしていくのが好ましい。
処理時間は、ブロック数とフィルター数の二乗とを掛け算したものにおよそ比例する。
10 blocks x 128 filtersと30 blocks x 384 filtersとでは、ブロック数3倍、フィルター数3倍なのでおよそ27倍の時間を要する。後者は前者に比べるとnps(1秒間の探索局面数)もおおよそ1/27倍になる。
将棋AIでは、npsが2倍になると+R140になるので27倍もnpsに差がつくと、単純に考えると R140×log(2)27 ≒ R666の差である。(後者のほうが弱い)
ところが、ブロック数やフィルター数が多いほうが局面評価の精度が高いので、長い時間になるとじわじわそれが利いてきて、どこかで強さが逆転するのである。
なので、チェスのほうでは、持ち時間に応じてベストなモデルファイルを選べと言うことになっている。
将棋のほうは、電竜戦で優勝したGCTはResNet10ch192(10 blocks × 192 filters)を採用していたが、これをResNet20ch256に上げる実験が本家dlshogiのほうではなされている。npsは28%ぐらいになってしまうので、よほどの長時間でないとその分を取り戻せないようだ。(いまのところ、WCSCや電竜戦の持ち時間では取り戻せないっぽい)
まとめ
囲碁、将棋、チェスのDeep Learningを使ったソフトでは普通はResNetが使われている。
ResNetの段数が40だと「40b」のように表記される。囲碁では40b、将棋では10bがいまのところ主流である。
電竜戦予選でGCTやdlshogiより上の順位だった二番絞りプレミアム生は20ブロックらしいです。V100とかのつよつよGPUが用意できるなら、将棋でもこのくらいの規模でNPS低下分がカバーできるほど強そうですね。
https://bleu48.hatenablog.com/entry/2020/11/22/062403
よくご存知で > 二番絞り
まあしかし、nps低下分(1/2だとして)、R140もの差があり、resnet10と20とでは持ち時間を倍にしても後者がR5すら稼げないようでなかなか大変でございます…。すごーく長い時間(か、すごく多い探索ノード数)だと後者のほうが良いはずなんですけどそれがどこなのかが問題で。
つまり、Yane Uxxxx Residual Ixxxxx Networkみたいな名前の何かが出来上がるのを待ってればいいんですか?w
xxxxには何が入るのだ?w
バンザイしてジャンプするやつですよね。以下の概念の話?『Googleの猫認識 (Deep Learning) – 大人になってからの再学習』http://zellij.hatenablog.com/entry/20130608/p1『最初の層は、エッジなどの局所的な』・・・あたり。『DL講義NEDO』http://ymatsuo.com/DL.pdf『34P:画像のエッジを認識』あたり。https://www.mhlw.go.jp/content/11601000/000341222.pdf『27P:エッジ→ヒゲ→猫の顔』あたり。
> バンザイしてジャンプするやつですよね。
ど、、どゆこと??
バレーボールのブロックです
おお、そういうことかw
Deep Learning系の将棋AIがten blocksでやっているのであれば、リアル車将棋はケンブロックとかでやるんでしょうか?w
今日は70点ぐらいの出来栄え…。
「今の人類は、昔の人類に7割くらい勝てるようになってるイメージ」
将棋でもソフトから学んで人間が強くなっているという話は聞きますが、実際そんなに強くなっているんですか?人間は基準の人がいないからみんなソフトの手を学習しちゃうとRに反映しないからわからないですよね。定跡のソフトの手の暗記部分で多少強くなっているかもしれないけど、それ以外に部分って強くなっているってデータあるのですか?
将棋の場合、序盤の感覚が多少マシになったところで終盤力がないと頓死するので、アマチュアレベルでは(AIから学んだところで)あまり棋力に影響ないと思います プロの世界は様相が異なるのでしょうけども。